아키텍처 구성

- Airflow , edge node
- airflow 를 통해 spark job submit이 가능하도록 따로 인스턴스를 두었다.
- EMR Cluster
- master 와 core를 하나씩 두고 task 노드를 spot 으로 하여 처리량에 따라 최소 비용으로 scalble 이 가능하도록 auto scaling 을 설정
- Bastion
- 외부에서 ssh 를 통해 작업이 가능하도록 해준다.
- NAT gateway
- private 망의 노드들이 패키지 설치 등을 위해 외부 망에 접근이 필요하므로 outbound 를 허용해준다.
- EFS
- 소스 등 파일시스템 공유를 위해
EMR 클러스터 생성
네트워크 인터페이스(eni) 생성
마스터 노드의 IP를 고정하기 위해서 IP 를 홀딩 해두는 목적으로 사용한다.
- EMR 이 뜰 때 eni 에서 세컨더리 프라이빗 IP 를 뻇어서 EMR 마스터 노드의 세컨더리 프라이빗 IP 로 할당
- EMR이 종료될 때 EMR 마스터 노드에서 세컨더리 프라이빗 IP 를 뻇어서 eni 세컨더리 프라이빗 IP 로 할당
위 동작은 EMR 클러스터가 생성될 때 bootstrap.sh 에서 수행한다.

클러스터가 사용할 서브넷을 넣는다
프라이빗 IPv4 주소 - 자동할당

프라이빗 IPv4 주소를 같은 대역으로 아무거나 중복되지 않게 넣는다. (중복이면 얼럿 뜸)
단계 1: 소프트웨어 및 단계

소프트웨어 구성 : emr 클러스터를 프로비저닝 하면서 기본적으로 깔아 줄 app 들이다.
app 버전 들은 emr 버전에 dependant 하게 정해진다.
여러 마스터 노드 : emr 클러스터의 마스터 노드를 이중화 할 것인지 선택한다.
체크를 하면 multi-az 를 사용하여 ha 를 구현한다.
AWS Glue 데이터 카탈로그 : 체크하면 glue 데이터 카탈로그를 외부 메타스토어(데이터를 먼저 저장하고 스키마를 입힌다.)를 사용한다.

스파크 설정구성, 파이선 설정구성 등을 티폴트로 정해준다. 이 설정은 최하위 우선순위로 작동한다.
s3 에서 JSON 로드를 통해 아래의 json 파일을 로드시킨다.
EMR 에서 돌아가는 app 의 디폴드 세팅값을 정해준다.
emr-software_settings-devstg-64.json
[
{
"configurations":[
{
"classification":"export",
"properties":{
"PYSPARK_PYTHON":"/usr/bin/python3"
}
}
],
"classification":"spark-env",
"properties":{
}
},
{
"classification":"spark-defaults",
"properties":{
"spark.num.executors":"2",
"spark.driver.maxResultSize":"0",
"spark.rdd.compress":"true",
"spark.network.timeout":"3600s",
"spark.shuffle.blockTransferService":"nio",
"spark.sql.broadcastTimeout":"3600",
"spark.shuffle.spill.compress":"true",
"spark.shuffle.compress":"true",
"spark.serializer":"org.apache.spark.serializer.KryoSerializer",
"spark.dynamicAllocation.minExecutors":"1",
"spark.dynamicAllocation.initialExecutors":"1",
"spark.executor.instances":"2",
"spark.dynamicAllocation.executorIdleTimeout":"120s",
"spark.dynamicAllocation.sustainedSchedulerBacklogTimeout":"3s",
"spark.executor.memory":"4g",
"spark.driver.memory":"4g",
"spark.kryoserializer.buffer.max":"512m",
"spark.master":"yarn",
"spark.driver.cores":"2",
"spark.executor.heartbeatInterval":"1800s",
"spark.dynamicAllocation.schedulerBacklogTimeout":"3s",
"spark.executor.cores":"2",
"spark.io.compression.codec":"lz4",
"spark.submit.deployMode":"cluster",
"spark.dynamicAllocation.maxExecutors":"10",
"spark.yarn.am.waitTime":"120s",
"spark.port.maxRetries":"200",
"spark.shuffle.service.enabled":"true",
"spark.yarn.historyServer.allowTracking":"true",
"spark.dynamicAllocation.enabled":"true",
"spark.history.fs.cleaner.enabled": "true",
"spark.history.fs.cleaner.interval": "1d",
"spark.history.fs.cleaner.maxAge": "14d"
}
},
{
"classification":"capacity-scheduler",
"properties":{
"yarn.scheduler.capacity.maximum-am-resource-percent":"0.9",
"yarn.scheduler.capacity.resource-calculator":"org.apache.hadoop.yarn.util.resource.DominantResourceCalculator"
}
},
{
"classification":"yarn-site",
"properties":{
"yarn.nodemanager.resource.memory-mb":"65536",
"yarn.nodemanager.pmem-check-enabled":"false",
"yarn.scheduler.maximum-allocation-mb":"65536",
"yarn.nodemanager.vmem-check-enabled":"false",
"yarn.nodemanager.localizer.cache.cleanup.interval-ms": "400000",
"yarn.nodemanager.localizer.cache.target-size-mb": "65536",
"yarn.resourcemanager.nodemanager-graceful-decommission-timeout-sec": "-1"
}
},
{
"classification":"mapred-site",
"properties":{
"yarn.app.mapreduce.am.resource.mb":"65536"
}
}
]

Concurrancy : step 이 어플리케이션을 구동하는 단위라고 생각할 수 있다.
concurrancy 를 설정하면 이 step 을 동시에 얼마나 구동할 지 정해줄 수 있다.
After last step completes
clusters enters waiting state : 클러스터가 종료 되지 않고 대기 해준다.
마지막 단계가 완료된 후 클러스터 자동 종료 : 클러스터가 종료 된다.
단계 2: 하드웨어
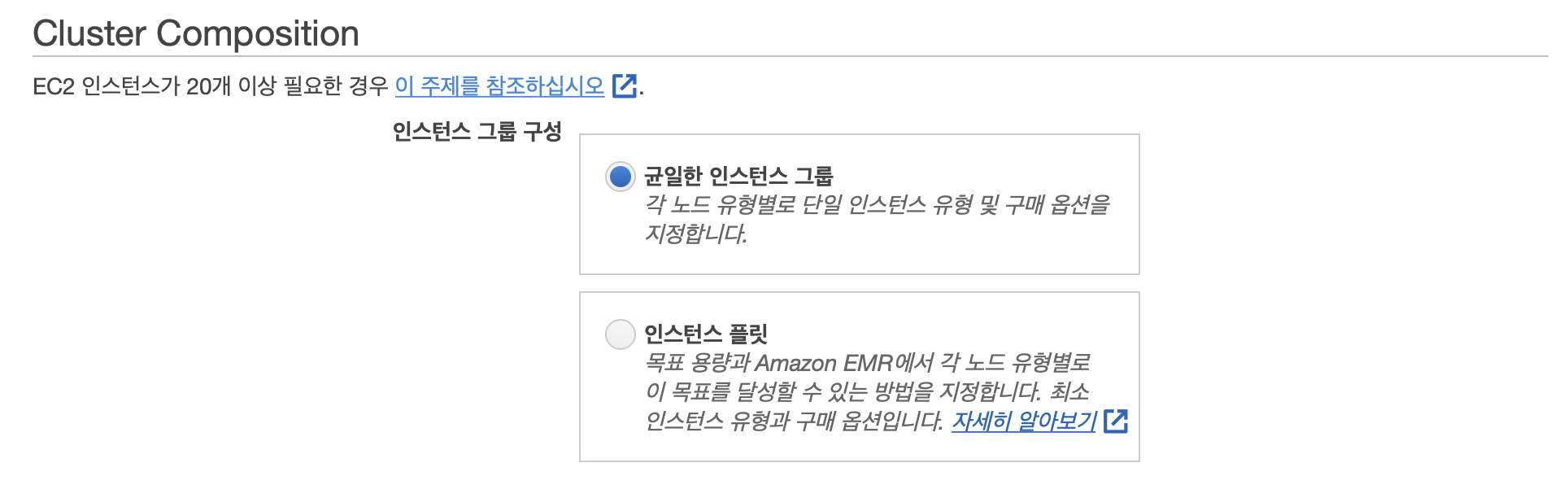
균일한 인스턴스 그룹 : 노드 유형별로 균일한 스펙의 인스턴스를 사용한다.

인스턴스 플릿 : 인스턴스 유형을 각각 지정할 수 있다.
유닛 : 코어수

Cluster scaling
클러스터 인스턴스의 스켈러블을 구현해준다.

Use EMR-manages scaling
코어와 테스크 유닛 등을 워크로드에 따라 지정한 숫자 범위 내에서 자동으로 조정해준다.
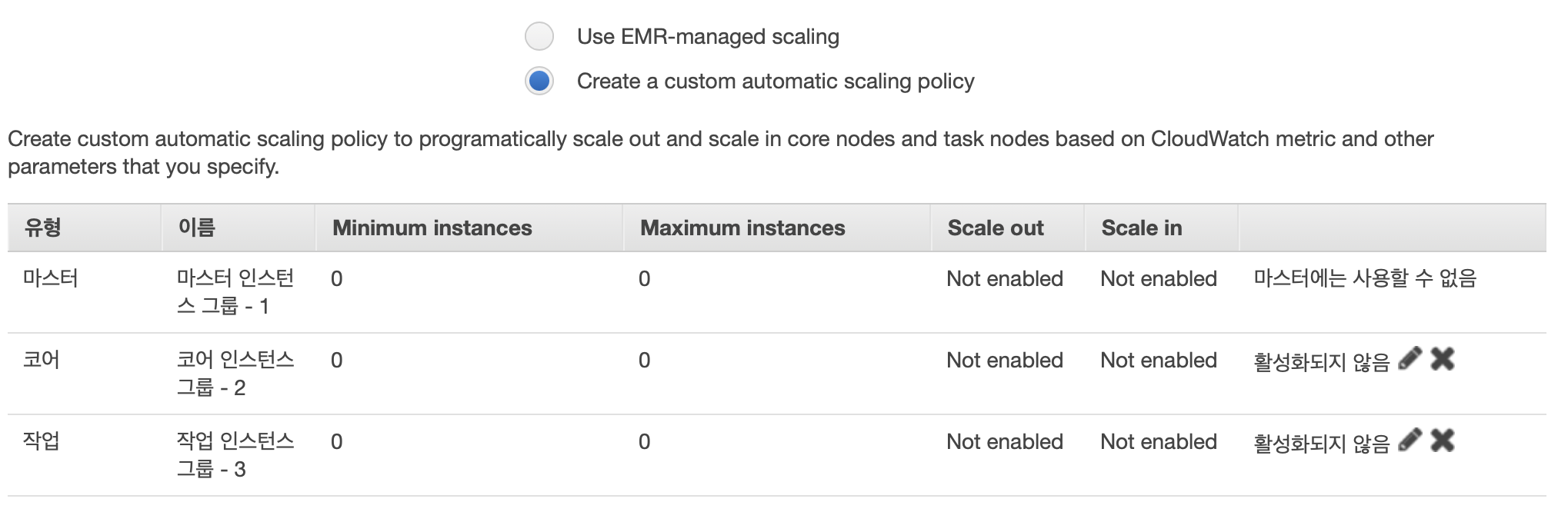
Create a custom automatic scailing policy
우측 연필 아이콘을 누르면

규칙에 따라 스케일 아웃, 인의 조건을 생성할 수 있다.
조건은 yarn의 리소스 점유율 등 여러가지가 트리거로 작동된다.
연속 횟수 : 5분 동안 트리거를 몇번 할 지
휴지 기간 : 트리거가 된 후 쿨다운을 어느정도 할 지

자동 종료
클러스터 유휴 된 이후 종료될 때 까지의 시간이다.

로깅 : EMR 이 생성될 때 까지의 로깅이 저장될 s3 path 이다.

태그 : emr 클러스터가 달게 되는 태그이다. 우리는 bootstrap.sh 에서 관련 처리를 해준다.
필요한 pip 패키지
requirement.txt
pandas==1.0.5
redis==2.10.6
redis-py-cluster==1.3.6
PyMySQL==0.9.3
pyarrow==1.0.0
#fastparquet==0.4.1
boto3==1.14.33
botocore==1.17.33
prettytable==0.7.2
requests==2.24.0
emr-bootstrap-practice.sh :: EMR 프로비저닝 할 때 수행하는 스크립트
#!/bin/bash
S3_PATH="s3://xxxxxxxxxxxxx/emr-config"
EFS_DOMAIN="fs-xxxxxxxx.efs.ap-northeast-2.amazonaws.com"
EMR_MASTER_IP="000.000.000.000"
#eni 세컨더리 IP 를 넣어 준다.
ENI_ID="eni-xxxxxxxxxxx"
#위에서 만든 eni ID 를 넣어준다.
#####################################################
# EMR Cluster Node
#####################################################
# install tools
sudo yum install -y python3-devel
sudo yum install -y jq
# install python package
aws s3 cp $S3_PATH/emr//practice-requirements/requirements.txt .
#패키지리스트와 버전들 정의
aws s3 cp $S3_PATH/emr/get-pip.py .
#pip3 를 쓰기 위해 pip3를 인스톨하는 스크립트 (안되는 경우가 있었다 함.)
python3 get-pip.py
export PATH=/home/hadoop/.local/bin/:$PATH
sudo pip3 install -r requirements.txt -t /usr/lib/python3.7/site-packages
#정의한 패키지들 설치
#####################################################
# MECAB write by sjh
#####################################################
sudo pip3 install mecab-python3==1.0.1
wget https://bitbucket.org/eunjeon/mecab-ko/downloads/mecab-0.996-ko-0.9.2.tar.gz
sudo tar xvf mecab-0.996-ko-0.9.2.tar.gz
cd mecab-0.996-ko-0.9.2
./configure
make -j 4
make check
sudo make install
sudo ldconfig
cd ..
sudo yum install -y automake
wget https://bitbucket.org/eunjeon/mecab-ko-dic/downloads/mecab-ko-dic-2.0.1-20150920.tar.gz
tar xvf mecab-ko-dic-2.0.1-20150920.tar.gz
cd mecab-ko-dic-2.0.1-20150920
./autogen.sh
./configure --with-mecab-config=../mecab-0.996-ko-0.9.2/mecab-config
make
sudo make install
# Set tag to EMR Cluster Node
aws s3 cp $S3_PATH/emr/emr-tag-practice.sh .
# 태그 일괄 적용 스크립트
perl -pi -e 's/\r\n/\n/g' emr-tag-practice.sh
sh emr-tag-practice.sh
# EFS Mount
sudo yum -y install nfs-utils
sudo mkdir /practice-efs
sudo chown hadoop:root /practice-efs
sudo mount -t nfs -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport $EFS_DOMAIN:/ /practice-efs
# KST 시간으로 설정
sudo ln -sf /usr/share/zoneinfo/Asia
#####################################################
# EMR Master Node
#####################################################
# Assign private ip to EMR Master Node
aws s3 cp $S3_PATH/emr/assign_private_ip.py .
python3 assign_private_ip.py $EMR_MASTER_IP $ENI_ID
assign_private_ip.py :: master node ip 할당
#!/usr/bin/python
#
#Copyright 2017-2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.
#
#Licensed under the Apache License, Version 2.0 (the "License"). You may not use this file
#except in compliance with the License. A copy of the License is located at
#
# http://aws.amazon.com/apache2.0/
#
#or in the "license" file accompanying this file. This file is distributed on an "AS IS"
#BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
#License for the specific language governing permissions and limitations under the License.
import sys, subprocess
is_master = subprocess.check_output(['cat /emr/instance-controller/lib/info/instance.json | jq .isMaster'], shell=True).decode('utf-8').strip()
if is_master == "true":
private_ip = str(sys.argv[1])
res_interface_id = str(sys.argv[2])
instance_id = subprocess.check_output(['/usr/bin/curl -s http://169.254.169.254/latest/meta-data/instance-id'], shell=True).decode('utf-8')
print("instance id: {}".format(instance_id))
interface_id = subprocess.check_output(['aws ec2 describe-instances --instance-ids %s | jq .Reservations[].Instances[].NetworkInterfaces[].NetworkInterfaceId' % instance_id], shell=True).decode('utf-8').strip().strip('"')
print("interface id: {}".format(interface_id))
# UnAssign Private IP from Reserved ENI
subprocess.check_call(['aws ec2 unassign-private-ip-addresses --network-interface-id %s --private-ip-addresses %s' % (res_interface_id, private_ip)], shell=True)
# Assign private IP to the master instance:
subprocess.check_call(['aws ec2 assign-private-ip-addresses --network-interface-id %s --private-ip-addresses %s' % (interface_id, private_ip)], shell=True)
subnet_id = subprocess.check_output(['aws ec2 describe-instances --instance-ids %s | jq .Reservations[].Instances[].NetworkInterfaces[].SubnetId' % instance_id], shell=True).decode('utf-8').strip().strip('"').strip().strip('"')
subnet_cidr = subprocess.check_output(['aws ec2 describe-subnets --subnet-ids %s | jq .Subnets[].CidrBlock' % subnet_id], shell=True).decode('utf-8').strip().strip('"')
cidr_prefix = subnet_cidr.split("/")[1]
# Add the private IP address to the default network interface:
subprocess.check_call(['sudo ip addr add dev eth0 %s/%s' % (private_ip, cidr_prefix)], shell=True)
# Configure iptablles rules such that traffic is redirected from the secondary to the primary IP address:
primary_ip = subprocess.check_output(['/sbin/ifconfig eth0 | grep \'inet\' '], shell=True).decode('utf-8').strip().split()[1] # new
# primary_ip = subprocess.check_output(['/sbin/ifconfig eth0 | grep \'inet addr:\' | cut -d: -f2 | awk \'{ print $1}\''], shell=True).strip() # old
print("primary_ip: {}".format(primary_ip))
subprocess.check_call(['sudo iptables -t nat -A PREROUTING -d %s -j DNAT --to-destination %s' % (private_ip, primary_ip)], shell=True)
# make shutdown script
subprocess.check_call(['mkdir -p /mnt/var/lib/instance-controller/public/shutdown-actions'], shell=True)
f = open("/mnt/var/lib/instance-controller/public/shutdown-actions/return_ip.sh",'w')
f.write('#!/bin/bash\n')
f.write('aws ec2 unassign-private-ip-addresses --network-interface-id %s --private-ip-addresses %s\n' % (interface_id,private_ip))
f.write('aws ec2 assign-private-ip-addresses --network-interface-id %s --private-ip-addresses %s' % (res_interface_id,private_ip))
f.close()
print("end of assign")
else:
print("Not the master node")
emr-tag-practice.sh :: 클러스터 인스턴스에 일괄 테그를 달아주는 쉘스크립트
#!/bin/bash
export IS_MASTER=$(cat /mnt/var/lib/info/instance.json | jq -r ".isMaster")
export INSTANCE_GROUP_ID=$(cat /mnt/var/lib/info/instance.json | jq -r ".instanceGroupId")
export CLUSTER_ID=$(cat /mnt/var/lib/info/job-flow.json | jq -r ".jobFlowId")
export INSTANCE_ID=$(wget -q -O - http://169.254.169.254/latest/meta-data/instance-id)
export INSTANCE_GROUP_TYPE=$(cat /mnt/var/lib/info/job-flow.json | jq -r ".instanceGroups | .[] | select( .instanceGroupId == \"${INSTANCE_GROUP_ID}\") | .instanceRole" | tr a-z A-Z)
export CURRENT_TAG_NAME=$(aws ec2 --region ap-northeast-2 describe-tags --filters Name=resource-id,Values=${INSTANCE_ID} | jq -r ".Tags | .[] | select( .Key == \"Name\") | .Value")
export NEW_TAG_NAME="${CURRENT_TAG_NAME}-${INSTANCE_GROUP_TYPE}"
export VALUE=“??????”
echo "IS_MASTER: $IS_MASTER"
echo "INSTANCE_GROUP_ID: $INSTANCE_GROUP_ID"
echo "CLUSTER_ID: $CLUSTER_ID"
echo "INSTANCE_ID: $INSTANCE_ID"
echo "INSTANCE_GROUP_TYPE: $INSTANCE_GROUP_TYPE"
echo "CURRENT_TAG_NAME: $CURRENT_TAG_NAME"
echo "NEW_TAG_NAME: $NEW_TAG_NAME"
aws ec2 create-tags --region ap-northeast-2 --resources ${INSTANCE_ID} --tags Key=Name,Value=${NEW_TAG_NAME}
aws ec2 create-tags --region ap-northeast-2 --resources ${INSTANCE_ID} --tags Key=Project,Value=EMR-PRACTICE
aws ec2 create-tags --region ap-northeast-2 --resources ${INSTANCE_ID} --tags Key=Customer,Value=${VALUE}
aws ec2 create-tags --region ap-northeast-2 --resources ${INSTANCE_ID} --tags Key=Biz Unit,Value=EMR-PRACTICE-CLUSTER
보안옵션

일반적인 보안 스터프 를 생성 적용 후 클러스터 생성
'일 > aws' 카테고리의 다른 글
| AWS Glue 활용기 #2 :: Glue job 개발 (0) | 2022.03.27 |
|---|---|
| AWS Glue 활용기 #1 :: Architect (0) | 2022.03.27 |
| Amazon EMR 구축 #1 :: 개념 정리 (0) | 2022.02.01 |
| AWS DMS Consistency Checking Application Concept (0) | 2022.01.11 |
| AWS Code Deploy + Jenkins + GitLab (0) | 2022.01.04 |


