DMS는 데이터베이스의 데이터를 빠르고 안전하게 aws 로 마이그레이션 할 수 있도록 도와준다.
DMS 는 이기종 간 마이그레이션도 지원한다.
여러 소스에서 s3 로 복제하여 데이터레이크 솔루션을 구축할 수도 있다.
여기서는 오로라 디비의 데이터 증분을 지속적으로 복제하는 DMS 를 구축 해본다.
DMS 는 네 가지를 생성하면 된다.
- 복제 인스턴스
복제를 수행할 컴퓨팅 파워이다. - 타겟 엔드포인트
데이터를 보낼 장소를 연결 - 소스 엔드포인트
데이터를 가져올 장소를 연결 - 태스크
복제 작업을 정의한다.
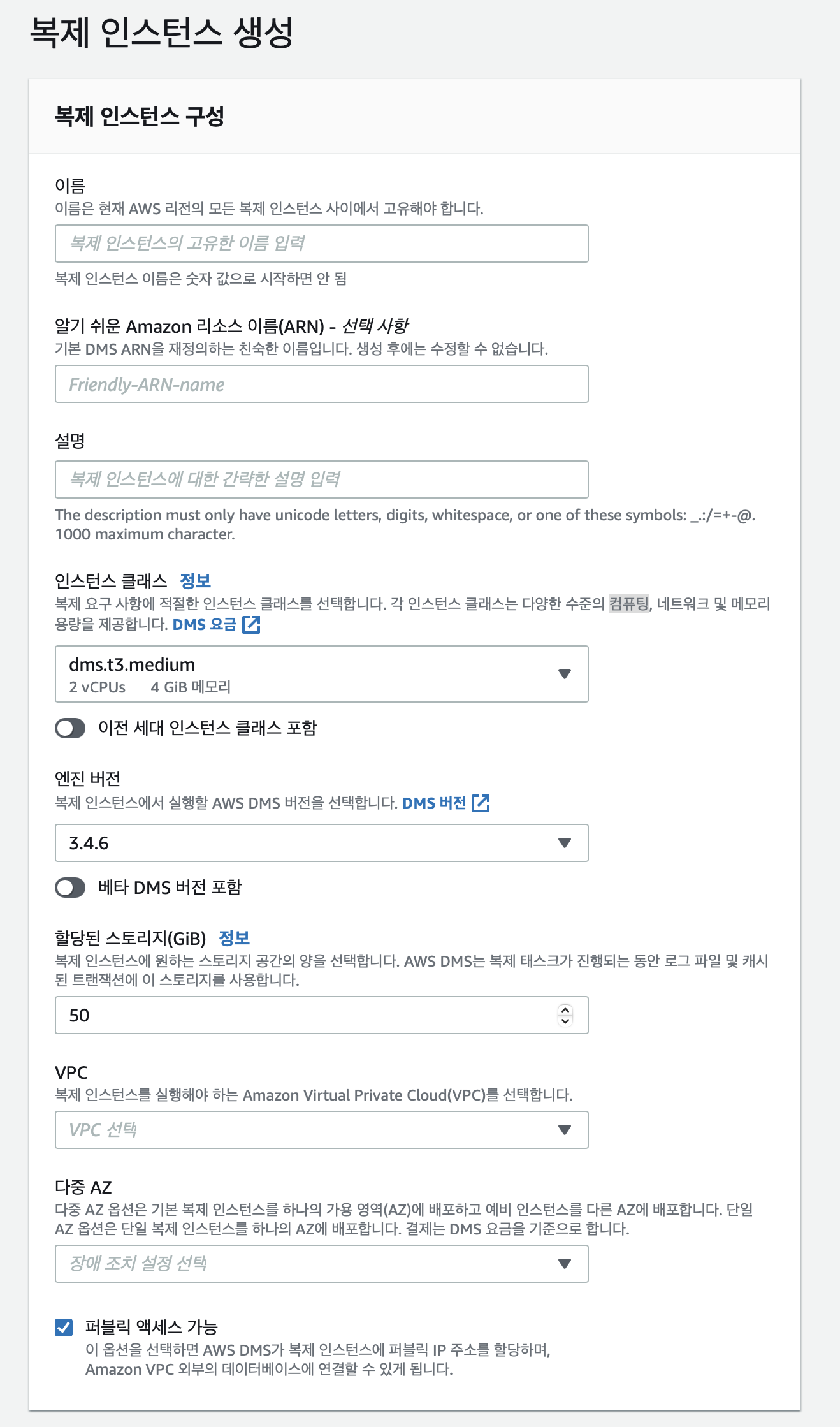
- 복제 인스턴스 생성
이름과 인스턴스 타입, 엔진 버전을 선택한다. 엔진은 3.4.1 이상으로 만들어야 s3 파티션 별 복제가 가능하다.
있어야 하는 VPC 를 선택하고 AZ 를선택한다. (운영은 다중 AZ)
- 엔드포인트
여기서는 소스/타겟에 해당하는 엔드포인트를 설정해준다.

식별자와 엔진, 서버 주소와 포트, 접속 계정 정보등을 입력해준다.
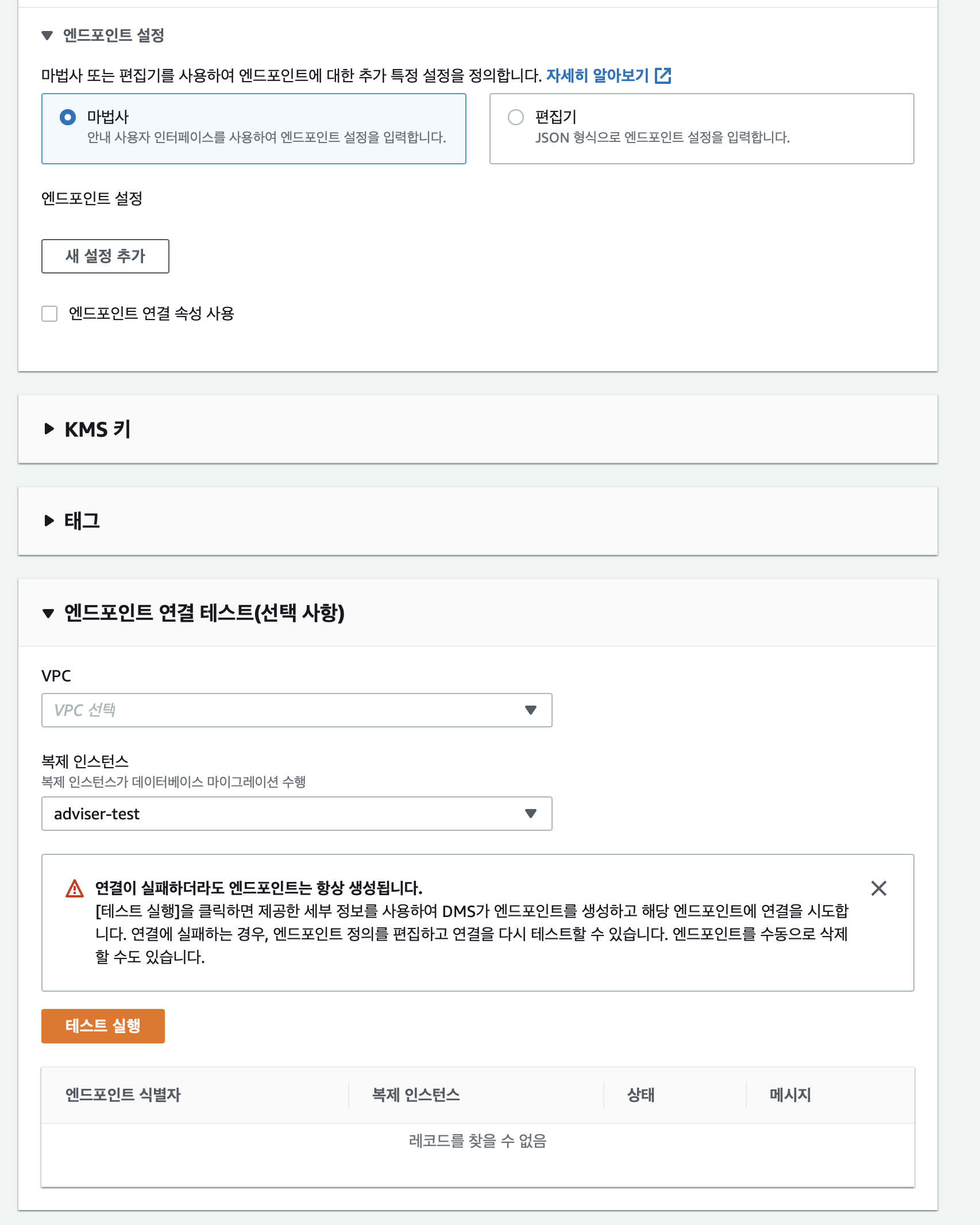
엔드포인트 설정은 기존에 만들어 두었던 설정 정보 json 이 없다면 마법사를 선택하고
KMS 키가 있다면 선택 해준다
엔드포인트 연결 테스트 에서는 복제 인스턴스 (실제로 복제를 프로세싱 해주는 인스턴스, DMS 복제 인스턴스 버전은 3.4.1 이상으로 해야 s3 복제가 가능해진다.) 와 VPC 를 선택해준 후 테스트를 해준다.
테스트가 완료되면 엔드포인트 생성을 클릭하면 끝.
- 타겟 엔드포인트 생성
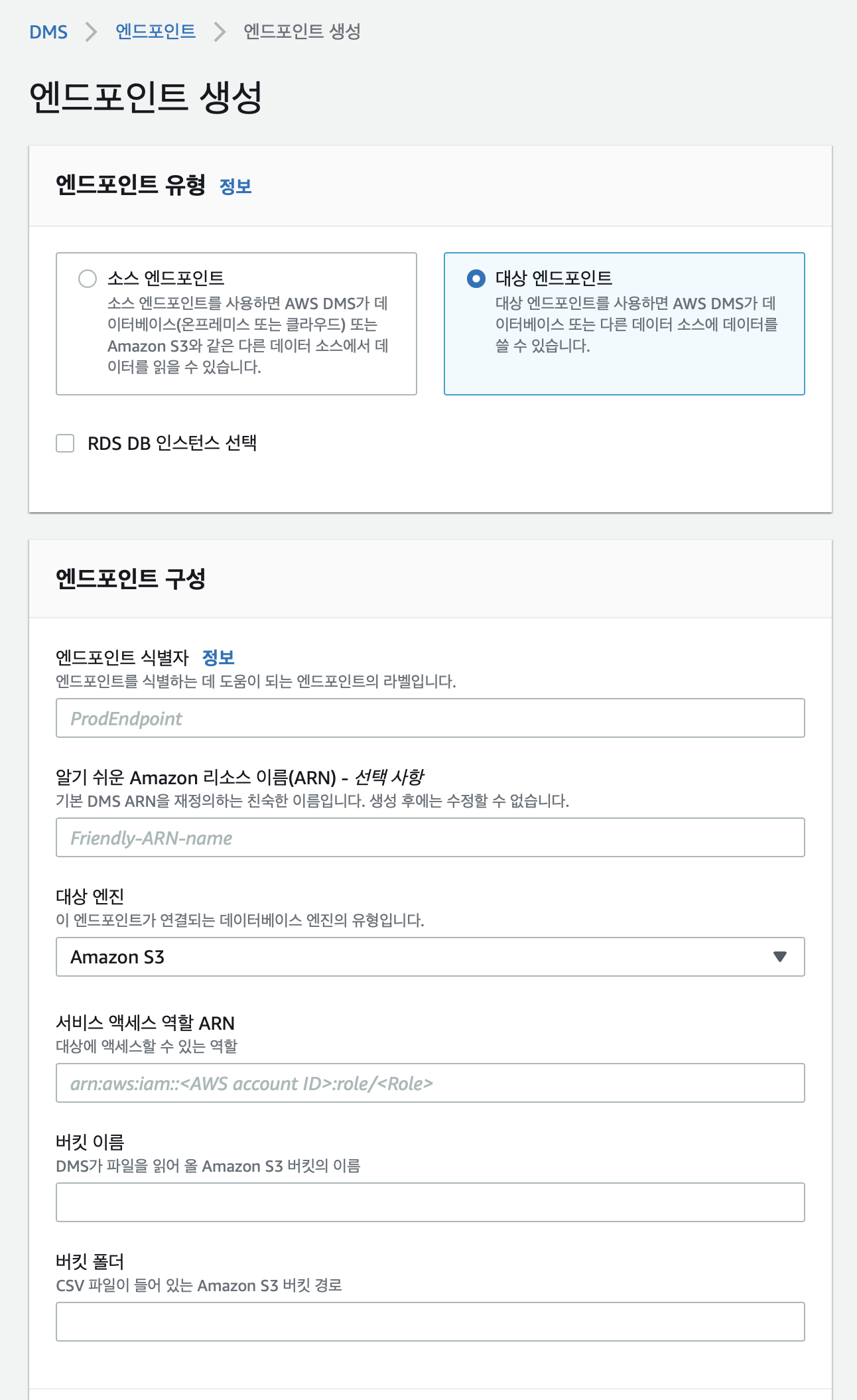
타겟 엔드포인트는 데이터가 도착해야 할 위치이다.
엔드포인트 이름 을 입력하고 대상 엔진에 Amazon S3를 선택한다. 그리고 원하는 버킷의 이름과 폴더를 입력

우리 서비스의 경우 에 해당하는 json 포맷을 입력하였다.
{
"CsvRowDelimiter": "\\n", : 로우 단위 식별자
"CsvDelimiter": ",", : csv 딜리미터
"CompressionType": "GZIP", : 압축 타입
"DataFormat": "parquet", : 데이터 타입
"EnableStatistics": true,
"DatePartitionEnabled": true, : 날짜별로 파티션 해서 넣어준다.
"DatePartitionSequence": "yyyymmddhh", : 날짜 포맷
"DatePartitionDelimiter": "slash" : 슬래쉬로 한정자
}
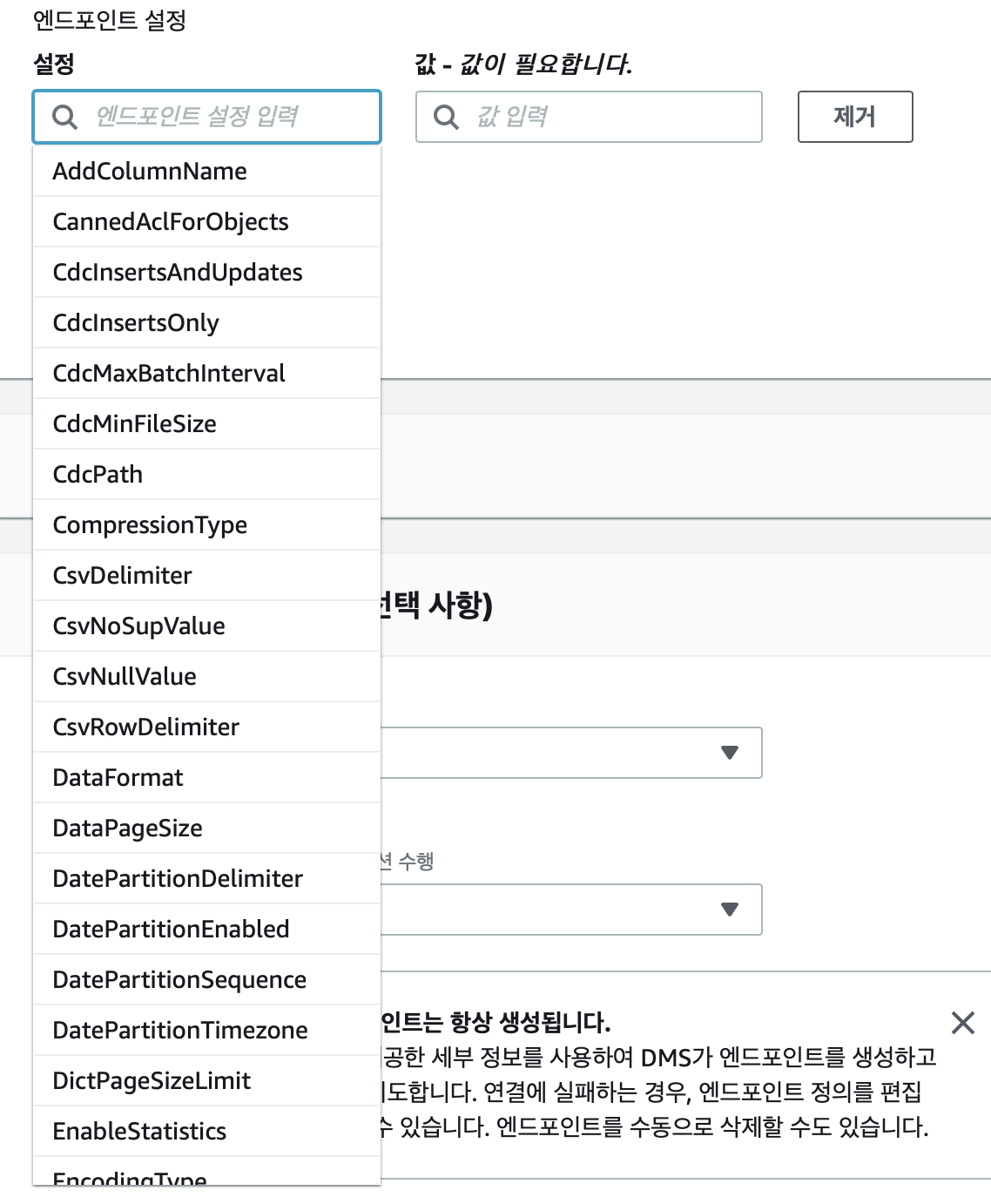
처음 구축시 필요하다면 엔드포인트 설정을 입력한다.
https://docs.aws.amazon.com/ko_kr/dms/latest/userguide/CHAP_Target.S3.html
공식 문서에 필요한 파라미터에 대한 설명이 있으므로 참조하여 넣자.

여기까지 완료가 되면 소스 엔드포인트에서 했던 것과 같이 VPC 와 복제인스턴스를 선택하고 테스트를 실행한 후 문제가 없다면 엔드포인트를 생성해준다.
- 테스크 생성
데이터 복제를 프로세싱하는 테스크를 생성한다.

테스크 식별자 : 테스크의 이름을 지어주면 된다.
복제 인스턴스 : 위에서 생성한 복제인스턴스를 선택해준다.
소스 엔드포인트 : 위에서 생성한 소스 엔드포인트 를 선택
대상 엔드포인트 : 위에서 생성한 타겟 엔드포인트를 선택 한다.
마이그레이션 유형 : 우리는 현재 데이터를 모두 이동시키고 지속적인 증분데이터를 복제할 것이므로 “기존데이터 마이그레이션 및 지속적인 변경사항 복제”를 선택한다.
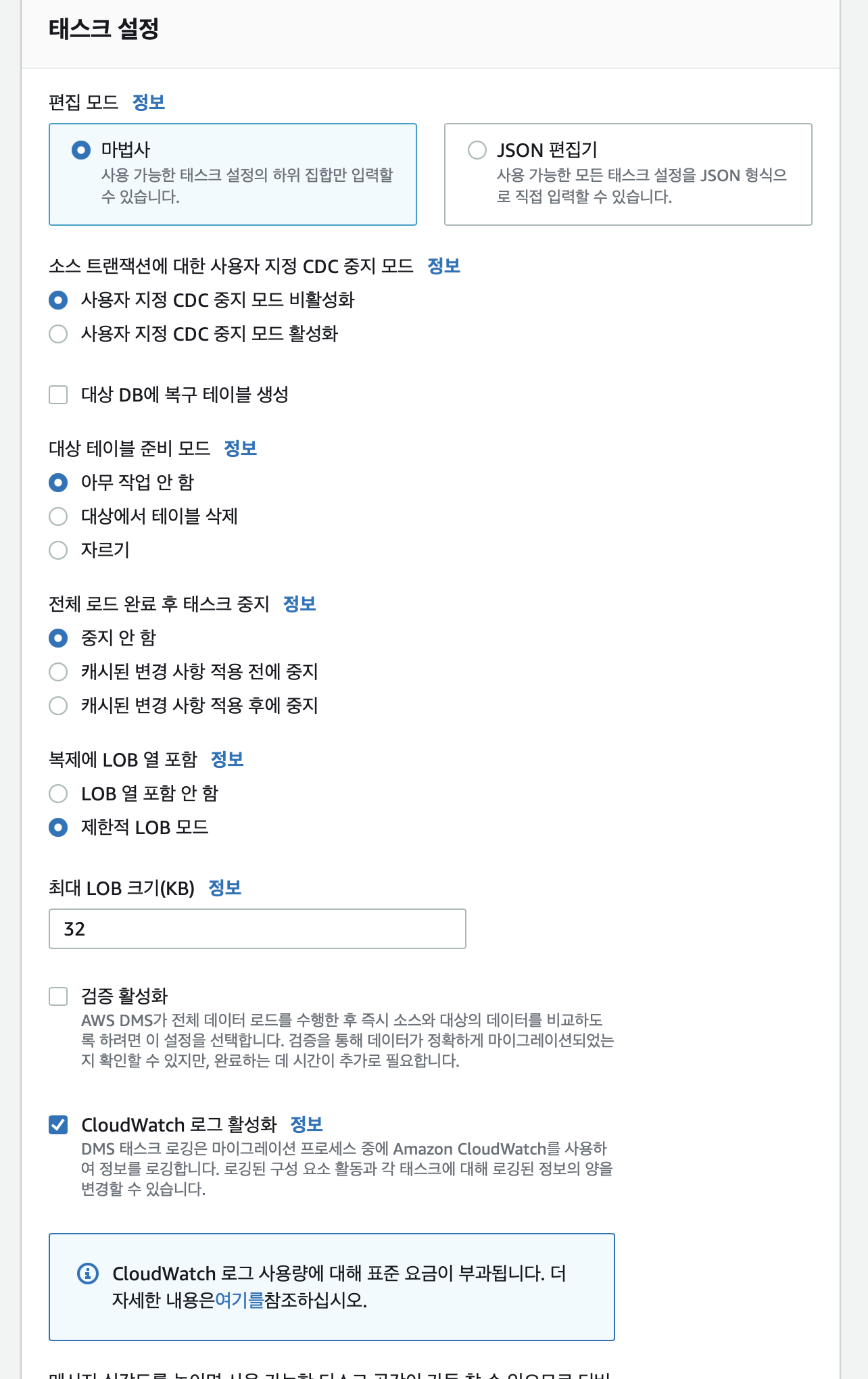
테스크 설정에서는 마법사를 선택하고
대상 테이블 준비모드는 아무작업 안함을 선택
아무 작업 안 함 - 테이블이 대상에 이미 있는 경우 그대로 남아 있습니다. 그렇지 않은 경우 AWS DMS에서 새 테이블을 만듭니다.
대상에서 테이블 삭제 - AWS DMS에서 테이블을 드롭하고, 그 위치에 새 테이블을 만듭니다.
자르기 - AWS DMS에서 테이블과 메타데이터를 그대로 두지만, 거기에서 데이터를 제거합니다.
cloud watch 는 활성화 한다.

고급 테스크 설정 을 누른 후
제어테이블에 대한 설정을 해준다.
제어테이블은 복제 테스크의 상태에 대한 메타데이터를 저장해주는 테이블이다.
복제상태, 일시중지된 테이블, 복제내역에 대한 활성화를 해준다.

테이블 매핑은 아래의 예제를 참고한다.
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": “DBNAME”,
"table-name": “TABLENAME”
},
"rule-action": "include"
},
{
"rule-type": "selection",
"rule-id": "2",
"rule-name": "2",
"object-locator": {
"schema-name": "DBNAME",
"table-name": "TABLENAME"
},
"rule-action": "include"
]
}
- 위 예제는 비식별화 컬럼이 존재하지 않아서 테이블 전체 데이터를 다 가져와도 될 때 사용
- schema-name은 DB명, table-name은 테이블 이름
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "DBNAME",
"table-name": "TABLENAME"
},
"rule-action": "include"
},
{
"rule-type": "transformation",
"rule-id": "2",
"rule-name": "2",
"rule-target": "column",
"object-locator": {
"schema-name": "DBNAME",
"table-name": "TABLENAME",
"column-name": “EXCEPTCOL”
},
"rule-action": "remove-column"
]
}
- 위 예제는 필요 없는 컬럼을 제외하고 S3로 마이그레이션 할 때 사용하는 예제
제외할 컬럼 지정 시 rule-type을 transformation, rule-target에 column, rule-action에 remove-column 을 명시해준다.

생성시 자동으로를 선택 후 태스크 생성을 누르면 태스크가 생성되고 자동으로 복제가 시작된다.
'일 > aws' 카테고리의 다른 글
| Amazon EMR 구축 #2 :: 프로비저닝 (0) | 2022.02.01 |
|---|---|
| Amazon EMR 구축 #1 :: 개념 정리 (0) | 2022.02.01 |
| AWS DMS Consistency Checking Application Concept (0) | 2022.01.11 |
| AWS Code Deploy + Jenkins + GitLab (0) | 2022.01.04 |
| [Python] AWS S3 Lifecycle 스토리지 클래스 변경 배치 (0) | 2021.08.28 |


